
Dies ist der mittlerweile vierte Post in der Reihe um End-to-End Organisation von Unternehmen und der damit einhergehenden Kennzahlenorientierung und Steuerung bzw. Regelung, den Unterschied werde ich im letzten Beitrag zu dieser Postreihe darlegen, von Unternehmen.
Im ersten Post habe ich ein paar grundlegende Fragestellungen zum Thema End-to-End Prozessbetrachtung in Unternehmen beantwortet, die ich dann im zweiten Post am Beispiel eines Handelsunternehmens konkretisiert habe. Dann habe ich im dritten Artikel einen kleinen gedanklichen Sprung vollzogen. Ich habe dort eingehend meine Sicht auf die Kategorien Kompliziertheit und Komplexität erläutert, welches letztendlich in eine Anpassung des bekannten Cynefin Modells resultierte. Die Anpassung des Modells ist aus meiner Sicht essentiell, um den angesprochenen Kategorienfehler zwischen Kompliziertheit und Komplexität zu erkennen und diesem nicht mehr erlegen zu sein.
| Beiträge zur Reihe “End-to-End Organisation und Steuerung/ Regelung von Unternehmen” | Link |
| Ist bei End-to-End Prozessen auch immer wirklich End-to-End drin? | |
| Eine konkrete End-to-End Prozessbetrachtung am Beispiel eines Handelsunternehmens | |
| Methoden passen immer, … | |
| Die Big Data Analytics Matrix | Dieser Beitrag |
| Maschinen kennen nur das “WAS”, niemals das “WARUM” | |
| Unreflektierte KPI Orientierung in Unternehmen ist wie “Malen nach Zahlen” | |
| Steuerung und Regelung von Unternehmen mit dem Viable System Model |
Am Beispiel Big Data Analytics möchte ich diesen Kategorienfehler erklären, was mich letztlich zu einer differenzierten Sichtweise auf Big Data und die darauf aufsetzenden Algorithmen verleitet. Das ist Bestandteil dieses Artikels.
In vielen Artikeln, Berichten und Büchern wird Big Data und die darauf aufsetzenden Algorithmen (Data Science) glorifiziert. Es gibt wenige Autoren, die Data Science differenziert betrachten. Damit meine ich, klare Grenzen von Data Science, gerade in Bezug zum Einsatz auf Menschen, aufzuzeigen, um dann erfolgreich einsetzen zu können. Diesen Fakt möchte ich mit diesem Post näher erläutern.
Hier einer dieser Artikel, in welchem das Heil in Data Science gesucht wird. Die Autoren glauben fest daran, mit Algorithmen beispielsweise den Frustrationslevel eines Menschen erkennen zu können, nämlich auf Basis seiner Cursorbewegung. Ich glaube nicht daran. Warum? Na Sie wissen bestimmt schon, wir vollziehen hier wieder einmal einen Kategorienfehler zwischen Kompliziertheit und Komplexität. Wie soll denn die Beziehung zwischen “Ich bin frustriert” und “Ich bewege meine Hand” aussehen? Hier betritt man Übergänge zwischen der materiellen und der seelischen Welt. Unsere Gehirnforscher glauben zwar hier Wirkmechanismen erkundet zu haben, allerdings merken sie nicht, dass sie bislang einen Kategorienfehler begehen. Unser Gehirn erzeugt aus dem Feuern von Neuronen, also aus Quantitäten, Qualitäten, wie “Ich liebe” oder “Ich hasse”. Wie das funktioniert ist bislang unbekannt. Man kann nicht mit Algorithmen aus der komplizierten Welt Sachverhalte der komplexen Welt erklären. Die Algorithmen setzen auf der Zweiwertigen Logik auf und diese lässt keine Kontextwechsel zu. Ich habe dies ja im dritten Post zu dieser Reihe eingehend an der Unterscheidung zwischen Kompliziertheit und Komplexität dargelegt.
Es gibt aber auch erfreulicherweise, leider noch zu wenige, Menschen, die diesen Fakt erkennen und thematisieren. Ich spreche hier stellvertretend Prof. Harald Walach an und zitiere aus seinem Artikel “Sowohl als auch” statt “Entweder-oder” – oder: wie man Kategorienfehler vermeidet
Die Wirklichkeit als Ganzes ist komplexer und lässt sich genau nicht mit solchen logischen Instrumenten komplett analysieren. … Weil unser Überleben als Art davon abhängig war, dass wir diesen logischen Operator so gut ausgeprägt haben ist die Gefahr groß dass wir nun alles so behandeln. … Mit Logik können wir nicht alle Probleme des Lebens lösen. … Geist und neuronale Entladungen sind Prozesse, die unterschiedlichen kategorialen Ebenen angehören, so ähnlich wie „blau“ und „laut“.
In meinem beruflichen Umfeld, dem Handel, lese und höre ich immer wieder, dass wir als Händler den Kontext unserer Kunden, wenn sie sich im Onlineshop bewegen, erkennen müssen, um ihnen bestmögliche Angebote machen zu können. Wir können den Kunden ja nicht fragen, was ihn gerade umtreibt. Also benötigen wir Algorithmen, die das erledigen. Und genau hier hake ich ein. Das geht nicht, weil wir mit etwas Kompliziertem, den Algorithmen, etwas Komplexes, den Gefühlszustand des Kunden, errechnen wollen. Dieser Fakt hat mich dazu veranlasst eine so genannte Big Data Analytics Matrix zu entwerfen, die man einsetzen kann, um Data Science reflektiert und gewinnbringend auf bestimme Anwendungsfälle anwenden zu können. Denn wie oft von mir betont, ich glaube an die Vorzüge von Big Data und den darauf aufsetzen Algorithmen, auch in Bezug zum Menschen, aber eben bitte differenzierter als bislang sehr oft von mir wahrgenommen.
Warum fällt es uns so schwer, den Kategorienfehler zwischen Kompliziertheit und Komplexität zu erkennen?
Mit Beginn unserer Schulbildung haben wir gelernt, Probleme zu analysieren und zu lösen. Es läuft nämlich stetig nach dem folgenden Muster ab: Teile ein Problem in handhabbare Teilprobleme → Löse diese Teilprobleme → Setze die Teillösungen zu einer Gesamtlösung zusammen! Nur dass in der Regel die Gesamtlösung dann rein gar nichts mehr mit dem Ausgangsproblem zu tun hat, erkennen wir in der Regel nicht. Darf ja gar nicht der Fall sein, denn diese analytische Herangehensweise ist quasi ein Naturgesetz, weil in der Schule gelernt. Alternativen wurden nicht angereicht.
Aber genau diese analytischer Lösungsweg hemmt uns Komplexität zu handhaben. Warum? Komplexität entsteht in erster Linie nicht durch die einzelnen Teile eines Systems an sich, sondern durch die Interaktion und die Vernetzung der Teile in dem System. Also nicht die Erhöhung der Anzahl der Teile in einem System ist vorrangig für den Anstieg der Komplexität in dem System verantwortlich. Das erkennt man an unserer Welt. Die Einwohneranzahl auf der Erde ist nicht in dem Maße gewachsen, wie unsere Komplexität zugenommen hat. Die Zunahme der Komplexität ist auf die gestiegene Vernetzung zurückzuführen. Dadurch, dass unsere Technologien es ermöglichen, das wir im World Wide Web nicht nur konsumieren, sondern uns auch mitteilen können und diese Mitteilungen jeden erdenklichen Winkel der Erde erreichen können und das auch noch in rasend schneller Geschwindigkeit, ist die Vernetzung und damit einhergehend die Komplexität rasend gestiegen.
Unsere analytische Vorgehensweise beim Lösen von Problemen befeuert uns also stetig und immer wieder, einen Kategorienfehler zwischen Kompliziertheit und Komplexität zu begehen. Wir zerstören durch das Zerlegen die Komplexität des Problems und befinden uns ab dann im komplizierten Raum, verlassen diesen nie wieder, wenden aber fröhlich die Lösungen auf Komplexität an. Auweia. Auch die derzeit hoch gelobten Methoden und Tools zum so genannten vernetzten oder ganzheitlichen Denken lösen dieses Dilemma nicht auf. Details dazu würden diesen Beitrag hier sprengen. Falls Sie Interesse haben verweise ich gerne auf den Artikel Unser Denkrahmen hat sich seit dem Mittelalter nicht weiter entwickelt.
Die Big Data Analytics Matrix
Aus diesem Grund habe ich wie gesagt Überlegungen zur Big Data Analytics Matrix unternommen, die unterhalb dargestellt zu finden ist.
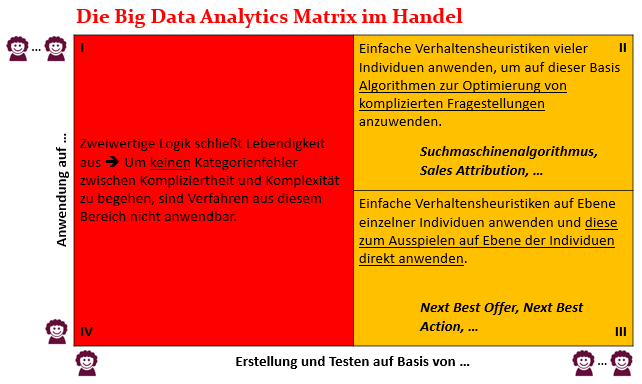
Die Matrix hat zwei Achsen. Die x-Achse stellt dar, auf welcher Basis, einzelne Menschen oder viele Menschen, Erkenntnisse direkt aus Daten und den darauf aufsetzenden Algorithmen inklusive eines Tests dieser gezogen werden sollen. Die y-Achse bildet ab, auf welcher Basis, einzelne Menschen oder viele Menschen, diese gewonnenen Erkenntnisse dann angewendet werden sollen. Ich gebe nachher noch einige Beispiele, alle aus dem Bereich des Handels. Dann wird diese Unterteilung sicherlich einleuchtender werden, wenn dies nicht jetzt schon der Fall ist.
Der rote Bereich der Matrix
An der Matrix erkennen wir, dass wir auf Basis von einzelnen Individuen keine Erkenntnisse maschinell über Algorithmen errechnen können. Tun wir das, begehen wir den von mir in der letzten Zeit oft angesprochenen Kategorienfehler zwischen Kompliziertheit und Komplexität. Das ist der gesamte linke rote Bereich der Matrix. Anwendungsfälle, die man gerne in diesen Bereich platzieren möchte, muss man über die anderen beiden Quadranten der Matrix, die ich nachher noch vorstellen werde, lösen.
Ich möchte den roten Quadranten I an einem Anwendungsfall näher erläutern, dem Sales Attribution Model im Handel. Als Händler ist man stets darauf bedacht, die Wirksamkeit eines Onlinekanals, SEA, SEO, PSM etc. in Bezug auf bestimmter im Unternehmen ausgelobter Ergebnisse zu ermitteln. In der Regel stellt man sich die Frage, wie viel ein bestimmter Onlinekanal zu einem letztendlichen Kauf eines Kunden beigetragen hat. Ich kaufe beispielsweise auf einem Onlineshop einen Fernseher. Es ist klar, dass ich irgendwie zu diesem Kauf inspiriert wurde. In der Regel spielen die Onlinekanäle, wie beispielsweise Preissuchmaschinen, eine große Rolle bei dieser Inspiration. Nun könnte es natürlich sinnvoll sein, zu ermitteln, wie groß die Wirkung eines jeden einzelnen Onlinekanals in Bezug zu diesem Kauf war, um dann aggregiert über alle Käufe aller Kunden die Gesamtwirkung aller Onlinekanäle gegenüberzustellen, um dann auf Basis dieser Wirkungsgrade das Marketingbudget auf die Kanäle zu verteilen.
Es gibt Bestrebungen, genau wie oben beschrieben, auf Basis aller einzelnen Käufe aller Kunden die Wichtigkeit der einzelnen Onlinekanäle zu ermitteln. Aber, ist das überhaupt machbar? Wir wollen auf Basis von Aktivitäten einzelner Individuen Erkenntnisse generieren und diese dann hoch aggregiert auf Viele als Entscheidungsbasis einsetzen. Da ich diesen Quadranten rot markiert habe, ist die Frage schnell mit “Nein” zu beantworten. Das ist nicht möglich. Aber warum?
Dazu möchte ich kurz einen Ausflug in die schönste Nebensache der Welt, dem Fußball, unternehmen. Die Sales Attribution ist, wie ich finde, sehr anschaulich am Fußball, in diesem Dokument erklärt. Stellt man sich im Fußball auch die Frage, wie groß der Anteil eines jeden Spielers an eigen erzielten Toren ist? Die Frage vielleicht schon, aber es wird in der Praxis nicht der Versuch unternommen, die Antwort auf Basis von Zahlen und Statistiken ausdrücken zu wollen. Warum? Weil es nicht funktioniert. Es wird im Kontext des Scoringsystems immer nur dem finalen Passgeber eines Tores ein Punkt zugeschrieben, zusätzlich zum eigentlichen Torschützen. Im WM-Finale im vorletzten Jahr hat nur Schürrle einen Scorerpunkt beim entscheidenden 1:0 durch Götze erhalten, obwohl man weiß, dass nicht nur Schürrle an dem Tor beteiligt war, und natürlich auch nicht nur Götze, der das Tor letztendlich geschossen hat. Warum ändert man wohl nicht das Scoringsystem? Ich glaube, dass man das sehr gerne tun würde, gerade weil mit einem solchen Zahlenkonstrukt zur Hand, sehr geniale Auswertemöglichkeiten zur Leistungsfähigkeit der einzelnen Spieler möglich wären. Man macht es nicht, weil man sich hier eingesteht, dass man nicht in der Lage ist, diese komplexen Vorgänge in Modelle und Zahlen zu transformieren. Hier nutzt man also noch das so genannte “Last-Klick Modell”, übertragen aus der Sales Attribution, wo immer nur der letzte Onlinekanal, der zu einem Kauf geführt hat, die volle Wirkung zugerechnet bekommt.
Erkennen Sie den Zusammenhang zum Attributionsmodell? Können Sie übrigens für jeden Ihrer Käufe, den Sie tätigen, genau beurteilen, wie groß der Einfluss der jeweiligen Kanäle war? Ich nicht. Und dann soll ein Modell dies auch noch für andere Menschen tun können? No Way.
Und der Unterschied zwischen dem Scoringsystem im Fußball und der Sales Attribution im Handel ist auch noch, dass man das Fußballspiel live und ganzheitlich betrachten kann. Aber selbst dann ist es uns unmöglich, eine solche Aussage im nach hinein zu treffen. Bei der Sales Attribution können wir den Kunden nicht beobachten, geschweige denn seine Gefühle und Motive wahrnehmen. Es existiert für die Sales Attribution in meinen Augen eine weit aus bessere Lösung als das bereits angesprochene Last-Klick-Modell. Deshalb können sie in der Big Data Matrix auch erkennen, dass ich dieses Beispiel in den rechten oberen Quadranten platziert habe. Es ist also vom Quadranten I in den Quadranten II gerutscht. Diesen Lösungsweg möchte ich Ihnen erläutern, wenn ich auf diesen Bereich der Matrix zu sprechen komme.
Ich möchte ein weiteren Beispiel im roten Bereich der Matrix anbringen, um den Quadranten IV zu erläutern, nämlich wo auf Individuenebene algorithmisch Erkenntnisse gewonnen werden sollen, und diese Erkenntnisse dann wieder auf Individuenebene in Handlungen transformiert werden sollen, wie beispielsweise bei Next Best Offer, oft als NBO abgekürzt. Bei NBO geht es um die Herausforderung, wenn sich ein Kunde oder User im Onlineshop befindet, ihm fortlaufend die besten Angebote zu unterbreiten. Auch hier gilt wieder, man kann den Kunden nicht fragen, was ihn gerade umtreibt. Also laufen Diskussionen dahingehend, das ermitteln zu wollen. Es geht um Fragestellungen, ob man dem Kunden einen Gutschein anbietet, um den bereits in den Warenkorb gelegten Artikel doch noch zu verkaufen oder ob der Kunde den Artikel sowieso kauft, auch ohne Gutschein.
Logisch, das sind alles relevante Fragestellungen für einen Händler, während ein Kunde sich im Onlineshop bewegt. Nur, sie sind eben nicht beantwortbar. Ob wir das nun gut finden oder nicht. Auch höre ich in diesem Zusammenhang immer wieder das Argument, man habe den Algorithmus ja getestet. Aber was genau testet man da eigentlich?
Wir kennen das Gesetz der großen Zahl aus dem Bereich der Wahrscheinlichkeitsrechnung, welches besagt, dass sich die relative Häufigkeit eines Zufallsergebnisses immer weiter an die theoretische Wahrscheinlichkeit für dieses Ergebnis annähert, je häufiger das Zufallsexperiment durchgeführt wird. Nehmen Sie hier das Beispiel “Würfeln”. Wenn man nur oft genug würfelt, kommen die jeweiligen Augenzahlen “1” bis “6” jeweils mit einer Wahrscheinlichkeit von 1/6 vor. Das kann man auch über Tests nachweisen, was bereits häufig genug getan wurde. Aber auch mit diesem Wissen im Hintergrund, sind wir noch lange nicht im Stande, die Augenzahl des nächsten Würfelvorgangs vorherzusagen.
Erkennen Sie den Zusammenhang zum Testen? Wir möchten einen Algorithmus benutzen, um auf Ebene von Individuen Erkenntnisse zu generieren, und diese dann nutzen, um auf Ebene der Individuen bestmögliche Entscheidungen auszuspielen. Getestet wird dieser Algorithmus dann auf der Ebene von Vielen. Klar, die Testgruppen müssen groß genug sein. Wir missachten hier das Gesetz der großen Zahl, wenn wir die Testergebnisse validieren? In diesem Zusammenhang ersetzt ein erfolgreicher Test also eine zu überprüfende Hypothese durch eine neue Hypothese.
Man sollte sich immer wieder vor Augen führen, dass man in einer komplexen Welt, in der wir uns ja nun einmal bewegen, weder die Zukunft vorhersagen, noch Ereignisse der Vergangenheit, auch wenn man sie beobachtet hat, erklären kann. Die Unmöglichkeit von Vorhersagen der Zukunft ist, denke ich, klar, auch wenn vorherrschende Planungs-, Budget- oder Business Case Diskussionen in Unternehmen eine andere Sprache sprechen. Komme ich zur Beschreibung der Vergangenheit. Komplexität ist unter anderem genau dadurch gekennzeichnet, dass man beobachtete Geschehnisse nicht auf lineare und lokale Ursache-Wirkungsbeziehungen reflektieren und deshalb nicht erklären kann. Warum etwas passiert ist oder eben nicht, lässt sich niemals genau bestimmen. Hier kann man auf Erkenntnisse der Chaostheorie zurück greifen.
Ich hoffe, ich habe Ihnen meine Sicht darlegen können, dass wir niemals Erkenntnisse auf Ebene der Individuen algorithmisch ermitteln dürfen, um diese dann als Handlungsanweisung entweder auf Einzelne oder auf Viele anwenden zu wollen. Es gibt andere Möglichkeiten, Big Data und Data Science erfolgreich und ohne Begehen eines Kategorienfehlers einzusetzen. Darauf komme ich nun zu sprechen.
Der gelbe Bereich der Matrix
Komplexe Vorgänge lassen sich durch sehr einfache Handlungsvorschriften beschreiben. Achtung! Hier bitte nicht dem Versuch erlegen sein, “einfach” und “einfach” zu verwechseln. Ich habe im vorigen Post zu dieser Reihe bereits ausgeführt, dass es sowohl in der Kategorie “kompliziert”, als auch in der Kategorie “komplex”, einfache Sachverhalte gibt, die aber nicht miteinander ob ihrer Schwierigkeitsstufe verglichen werden dürfen. Tut man es, dann, ja sie wissen schon: Kategorienfehler. Es ist ähnlich zu der Fragestellung: “Welche Farbe ist größer, blau oder rot?” Deshalb habe ich auch vor geraumer Zeit einen Post mit dem Titel Komplexitäten entstehen aus Einfachheiten, sind aber schwer zu handhaben verfasst. Aus diesem Post möchte ich kurz zitieren.
Wir Menschen sind der festen Überzeugung, kommend aus einer mechanistisch-technokratischen Sicht, die im 17. Jahrhundert mit dem Aufblühen der Naturwissenschaften geweckt wurde, dass komplexes Verhalten oder komplexe Zusammenhänge stets aus komplexen Verfahrensanweisungen oder komplexen Teilen bestehen muss. Dass wir hier einem Irrglauben erlegen sind, möchte ich an einem Beispiel aus der Praxis belegen. Es geht um das Fangen eines Balles, was ein sehr komplexer Vorgang ist. Würden wir als Ballfänger beginnen, diesen Vorgang in seine Einzelteile zu zerlegen, diese zu evaluieren und zu lösen und dann letzten Endes zu einem Algorithmus zu integrieren, welche das Verhalten abbildet, müssten wir nicht nur ballistische Berechnungen anstellen, sondern auch noch die aktuellen Umgebungsparameter wie Windrichtung und -geschwindigkeit, den aktuellen Luftwiderstand des Balles, die Oberflächenbeschaffenheit des Balles, die Beschaffenheit des Bodens, auf dem wir uns bewegen usw. mitberechnen. Würde diese Prozedur ausgeführt, ganz abgesehen davon die notwendigen Variablen überhaupt messen zu können, wäre der Ball längst auf dem Boden, während wir noch rechnen würden. Des Weiteren beobachten wir selbst Kinder, die von solchen Berechnungen kein Wissen haben, dass sie in der Lage sind, Bälle zu fangen. Die intuitive Regel, die wir Menschen anwenden ist jedoch sehr einfach. Sie lautet: Richte den Blick auf den Ball, beginne zu laufen und passe die Geschwindigkeit so an, dass der Blickwinkel zum Ball konstant bleibt.
Dieses Thema hat Stephen Wolfram, der Erfinder von Mathematica, aufgegriffen und eine neue Art der Wissenschaft, a new kind of science, wie er es nannte, kreiert. Das gleichnamige kostenlose Buch findet man hier. Warum hat Wolfram diese Wissenschaft wohl so genannt? Wir erkennen am Beispiel des Ballfangens, dass Lösungen zu bestimmen Problemstellungen analytisch nicht herleitbar sind. Wir benötigen eine komplett andere Art der Herangehensweise, eine neue Wissenschaft.
Bedienen kann man sich in diesem Kontext heuristischen Modellen, die eine Aussage darüber treffen, wie Menschen sich in der Regel in bestimmten Kontexten bewegen. Eigen sind diesen Modellen, dass sie nicht algorithmisch mithilfe von Daten auf Individuenebene hergeleitet sind, sondern auf Beobachtung, Reflektion und Erfahrung von Menschen über Menschen fußen. Diese Art von Modellen liegen deshalb auch in den rechten beiden Quadranten der Matrix. Hier eignen sich beispielsweise die Systemgesetze oder auch die Systemarchetypen von Senge als Einstieg.
Nun komme ich zu meinen Überlegungen im Kontext Attributionsmodell zurück und möchte Ansätze offenbaren, die auf Heuristiken und nicht auf datenbasierte Algorithmen beruhen, um hier besser als “Last-Klick” zu sein. Wir haben oben bereits ausgeführt, dass die Sales Attribution vom roten Quadranten I in den gelben Qadranten II rutschen sollte, weil man nicht daten- und algorithmenbasiert auf Kundenebene Erkenntnisse generieren kann. Was sind aber nun Ansätze für den Quadranten II für diesen Anwendungsfall?
Ich würde fortwährend Daten sammeln, die Aussagen darüber treffen, über welche Einstiegspunkte Kunden und User den Onlineshop betreten haben und welche letztendlich zu einem Kauf geführt haben. Auf dieser Basis würde ich eine Gruppe von Experten ein Ranking zwischen den verschiedenen Onlinekanälen erstellen lassen. Die Scores aller Onlinekanäle aufaddiert muss natürlich 1 ergeben. Nach festgelegten Zeitpunkten würde ich diese Rankings mittels neu gewonnener Daten von den Experten validieren lassen. That`s it. Sehr einfach, oder? Besser als das Last-Klick Modell und vor allem auch besser als Bestrebungen, jeden einzelnen Kauf eines jeden einzelnen Kunden über seine Customer Journey auf die Wichtigkeit der Onlinekanäle zu reflektieren, weil man eben keinen Kategorienfehler begeht.
In diesem Quadranten habe ich ebenfalls den Suchmaschinenalgorithmus platziert, welchen man über Heuristiken optimieren kann. Das möchte ich ein wenig ausführen. Einen Suchmaschinenalgorithmus auf einem Onlineshop lässt sich nach mehreren Kriterien optimieren. Beispielsweise sollten, wenn Kunden und User nach bestimmten Artikeln suchen, die Artikel am besten verkauft werden, die abverkauft werden müssen oder von denen noch sehr viele auf Lager sind oder über denen der Nettoabsatz oder der Nettoumsatz maximiert wird. In diesem Kontext bewegen wir uns noch rein im komplizierten, da “toten” Bereich. Hier lassen sich dann auch bekannte mathematische Optimierungsverfahren einsetzen. Aber dann ist man ja noch nicht am Ende, denn der Mensch ist ja noch nicht inkludiert. Dann wird es nämlich komplex und die Mathematik hilft nicht weiter. Es ist ja nicht nur eine Frage des Suchens und des Darstellens der Artikel in der Suchergebnisliste, sondern der Mensch interagiert ja mit dieser Liste. Und hier kann man die folgende Heuristik heranziehen:
- Wir Menschen klicken je weniger in der Suchergebnisliste auf Artikel, je weiter diese unten oder hinten in der Liste stehen.
Zusammen mit dieser Heuristik lässt sich dann die Suchergebnisliste erstellen. Wenn man also den Suchalgorithmus nach dem Kriterium optimiert, dass der Nettoabsatz maximiert werden soll, müssen genau die Artikel, die dieses Optimierungskriterium befeuern, oben in der Suchergebnisliste platziert werden.
Komme ich nun zum gelben Quadranten III der Matrix und zu unserem Anwendungsbeispiel NBO zurück. Wie bereits ausgeführt hilft auch hier unsere zweiwertige Mathematik nicht, um den wie so oft titulierten Kontext eines Kunden, wenn er sich im Onlineshop befindet, zu errechnen, um ihm ein nächst bestes Angebot zu unterbreiten. Denn unsere zweiwertige Mathematik ist auf Monokontexturalität aufgebaut. Was sind hier gute Heuristiken, die man zu Rate ziehen könnte?
- Artikel, die ein Mensch bereits gekauft hat, wird er wahrscheinlich nicht noch einmal kaufen.
- Artikel, die ein Mensch schon einmal retourniert hat, wird er wahrscheinlich nicht noch einmal kaufen.
- Sucht ein Mensch einen Artikel, der ausverkauft ist, ist es wahrscheinlich, dass er ähnliche Artikel von Form und Farbe kaufen würde, die er aber noch nicht gekauft hat.
- Artikel, die nicht auf Lager sind, sollten nicht angeboten werden.
- Artikel, für die ein Kunde in einer bestimmten Kategorie affin ist, sollte man ihm anbieten, wenn er in dieser Kategorie sucht.
Ihnen fallen bestimmt weitere Heuristiken ein.
Was haben die beiden gelben Quadranten II und III gemein? Man kombiniert oft Heuristiken, um komplexe Sachverhalte das Menschen zu handhaben mit Algorithmen, die im Komplizierten liegen. Auch bei Heuristiken helfen Daten, aber im Zusammenhang mit Denkprozessen des Menschen, niemals im Zusammenhang mit darauf rechnenden Algorithmen. Ich hoffe die Anwendungsbeispiele haben das verdeutlicht. Daher liegen auch diese Quadranten nicht im grünen Bereich.
Sie fragen sich wahrscheinlich, ob es auch einen grünen Quadranten geben würde oder könnte. Ja, und zwar immer nur dann, wenn der Mensch in den jeweiligen Anwendungsbeispielen, wo Data Science angewendet werden soll, keine Rolle spielt, wenn man sich also ausschließlich im komplizierten Bereich bewegen würde. Dazu jetzt einige abschließende Bemerkungen.
Der grüne Bereich angedeutet
Dieses Thema? beschäftigt mich seit 1999. In diesem Jahr habe ich in einer Firma meine Diplomarbeit geschrieben. Diese Firma hat eine Maschine entwickelt, die aufgenommene Bilder aus Blitzgeräten im Straßenverkehr automatisch durchzieht, archiviert und daraus Mahnschreiben generiert. Ein Problem dabei war das Erkennen der Nummernschilder, vor allem wenn diese verdreckt waren. Hier kam ich ins Spiel. Ich habe im Rahmen meiner Diplomarbeit ein Lernverfahren für ein Künstlich Neuronales Netz (KNN) programmiert, welches genau für diese Bilderkennung eingesetzt wurde. Dieses Lernverfahren setzte auf der Backpropagation auf und funktionierte auch sehr gut. Dieses Modell lag im grünen Bereich, da nichts in Bezug auf den Menschen optimiert werden sollte. Es ging einzig und allein um Bilderkennung.
Allerdings war das auch der Startpunkt für mich, kritisch die Strömungen rund um die Künstliche Intelligenz, vor allem im Kontext der Modellierung von Lebendigkeit, zu sehen. Ich habe nämlich hart hinterfragt, was dieses von mir programmierte KNN eigentlich tut, wozu es gut ist und wo die Hürden liegen. Dieser Post stellt letztendlich die Zusammenfassung all meiner Ideen und Gedanken in diesem Kontext über all die Jahre dar.
Im kommenden Beitrag dieser Blogpostreihe werde ich nun, wo wir nun ein bisschen mehr in die Big Data Welt eingetaucht sind, eine Brücke schlagen zur Kennzahlenorientierung und Steuerung von Unternehmen. Gerade das Thema Echtzeitsteuerung von Unternehmen, welches derzeit gerade enorm gehyped wird, wird auf Basis der gewonnenen Erkenntnissen reflektiert, und, na klar, differenziert beleuchtet. Denn, Echtzeit geht ja nur über Automatismen in der Datenverarbeitung, um Erkenntnisse zu generieren. Und gerade hier haben wir in diesem Post die Grenzen ausgelotet.
Also, seien Sie gespannt. Ich bin es. 🙂
 (5 Bewertung(en), Durchschnitt: 5.00 von 5)
(5 Bewertung(en), Durchschnitt: 5.00 von 5)
Pingback: Reise des Verstehens » Blog Archiv » Methoden passen immer, …
Pingback: [Reise des Verstehens] Die Big Data Analytics Matrix
Pingback: Reise des Verstehens » Blog Archiv » Maschinen kennen nur das “WAS”, niemals das “WARUM”
Pingback: Reise des Verstehens » Blog Archiv » Ist bei End-to-End Prozessen auch immer wirklich End-to-End drin?
Pingback: Reise des Verstehens » Blog Archiv » Eine konkrete End-to-End Prozessbetrachtung am Beispiel eines Handelsunternehmens
Pingback: Reise des Verstehens » Blog Archiv » Unreflektierte KPI Orientierung in Unternehmen ist wie “Malen nach Zahlen”
Conny,
ich finde Deinen Post super! Aus Deinen Erfahrungen mit und Reflektionen zur Big-Data-Anwendung schlägst Du eine Brücke zur Philosophie des Geistes, genauer zu John Searle.
Searle diskutiert die Möglichkeiten und Grenzen von künstlicher Intelligenz. Er weißt darauf hin, dass menschliches Denken eine qualitative Dimension hat, die Algorithmen und Maschinen nicht haben. Das sind die sogenannten “qualia” (Englisch): Wie fühlt es sich an?
Qualia, oder Gefühle, sind nicht nur Begleiterscheinung des menschlichen Denken und Handeln, sondern beeinflussen es: “Fühlt es sich gut/schlecht an, dieses Produkt zu kaufen?” oder: “Ich muss schneller/langsamer laufen, um den Ball zu fangen!” Wenn man nun einen menschlichen Denkprozess oder eine Handlung algorithmisch beschreibt, dann verschwinden die qualia. Genau so wie die PS eines Motors verschwinden, wenn man ihn in seine Einzelteile zerlegt.
Moin Tobias,
ganz lieben Dank für Deine Replik.
BG, Conny
Pingback: Geht mit Künstlicher Intelligenz nur „Malen nach Zahlen“? – Data Science Blog
Pingback: Geht mit Künstlicher Intelligenz nur „Malen nach Zahlen“? – Data Science Blog (German only)