
Ich habe im letzten Post Die Big Data Analytics Matrix der Artikelserie zu End-to-End Organisation von Unternehmen und der damit einhergehenden Kennzahlenorientierung und Steuerung bzw. Regelung, dargelegt, dass einzig und allein über Daten und Algorithmen, also ohne dass der Mensch über seine Kognition eingreift, niemals Erkenntnisse über Beweggründe für bestimmte Handlungen eines Menschen eruiert werden können. Damit habe ich den roten Bereich der Big Data Analytics Matrix aufgespannt. Ich habe in einigen nachgelagerten Gesprächen dazu festgestellt, dass ich diese Hypothese aus meiner Sicht noch weiter beleuchten sollte. Das möchte ich mit diesem Post tun.
| Beiträge zur Reihe “End-to-End Organisation und Steuerung/ Regelung von Unternehmen” | Link |
| Ist bei End-to-End Prozessen auch immer wirklich End-to-End drin? | |
| Eine konkrete End-to-End Prozessbetrachtung am Beispiel eines Handelsunternehmens | |
| Methoden passen immer, … | |
| Die Big Data Analytics Matrix | |
| Maschinen kennen nur das “WAS”, niemals das “WARUM” | Dieser Beitrag |
| Unreflektierte KPI Orientierung in Unternehmen ist wie “Malen nach Zahlen” | |
| Steuerung und Regelung von Unternehmen mit dem Viable System Model |
Stimmt man mit der oben genannten These nicht überein, dann glaubt man an die folgende.
Führen 2 Menschen identische Handlungen aus (materielle Welt), dann basieren diese Handlungen auch auf den identischen Beweggründen (seelische Welt).
Ich negiere diese Hypothese ganz klar, was ich nachgelagert belegen möchte. Warum? Weil ich an dieser Stelle keinem Kategorienfehler zwischen Komplexität und Kompliziertheit erlegen sein möchte. Hier passt der blinde Fleck der Hirnwissenschaft.
Aus dem reinen Feuern von Neuronen im Gehirn des Menschen (Quantitäten), können wir Stand heute, trotz aller technologischer und wissenschaftlicher Fortschritte, noch keine Gefühlszustände (Qualitäten), wie “Ich liebe” oder “Ich habe Heimweh”, ableiten.
Oder wie es Heinz von Förster in seinem lesenswerten Buch Wissen und Gewissen sehr schön beschreibt.
… da draußen gibt es nämlich in der Tat weder Licht noch Farben, sondern lediglich elektromagnetische Wellen; da draußen gibt es weder Klänge noch Musik, sondern lediglich periodische Druckwellen der Luft; da draußen gibt es keine Wärme und keine Kälte, sondern nur bewegte Moleküle mit größerer oder geringerer durchschnittlicher kinetischer Energie usw.
Die Schnittstelle zwischen der materiellen und der seelischen Welt ist bislang nicht ergründet. Diese Schnittstelle müsste aus Quantitäten Qualitäten erzeugen. Unsere Mathematik kann aber genau das nicht, da sie auf Monokontexturalität basiert. Die folgende Abbildung stellt diese Beziehung dar.
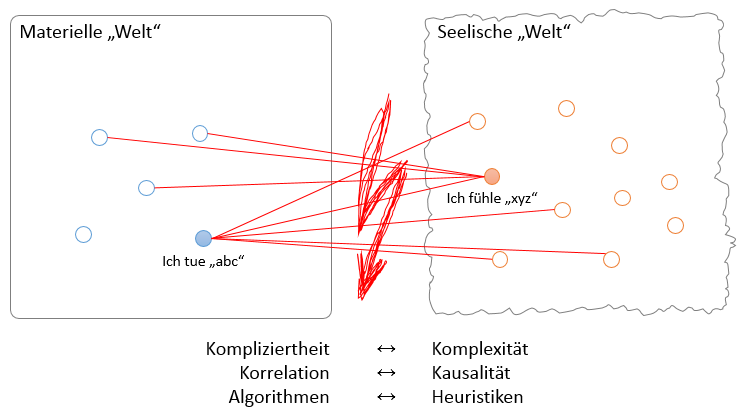
Bei Maschinen existiert diese Konstellation nicht. Klar, dort fehlt die seelische Welt. Wenn also 2 Maschinen das gleiche tun, dann “fühlen” diese auch gleich, da sie den gleichen Kontext haben. Sie haben ja nur einen, nämlich im Sinne dessen wofür sie geschaffen wurden. Natürlich hat beispielsweise ein Schachcomputer niemals den gleichen Kontext wie ein Parkassistent im Auto. Obwohl jeder der beiden Maschinen genau einen hat: Monokontexturalität. Daher würden wir auch nie auf die Idee kommen zu meinen, dass der Parkassistent und der Schachcomputer sich gleich verhalten.
Mit Big Data und den darauf aufsetzenden Algorithmen kann man Aktionen von Menschen aus der Vergangenheit beobachten, allerdings ohne diese zu werten. Es wird also ausschließlich gemessen. Die materielle Welt kann also komplett abgebildet werden. Das “Was” (Korrelation) wird beantwortet. Diese Beobachtungen lassen sich aber nicht bewerten, da der Kontext, also die seelische Welt der Menschen, unsichtbar bleibt. Das “Warum” (Kausalität) bleibt im Verborgenen. Dementsprechend lassen sich auch über Algorithmen keine Erkenntnisse generieren. Für das “Warum” benötigt man den Menschen. Und nur wenn man das “Warum” beantwortet, kann man Erkenntnisse aus Daten gewinnen.
Sie können an der obigen Abbildung auch sehr schön den Bezug zum Kompl-IZ-EX Modell herstellen. Jetzt verstehen Sie vielleicht auch noch mehr, warum ich Kompliziertheit und Komplexität nicht wie im Cynefin-Modell auf einer Kategorienebene dargestellt habe.
Wie gesagt, die Schnittstelle zwischen der materiellen und seelischen Welt ist nicht ergründet. Setzen wir Algorithmen, die einzig und allein in der materiellen Welt ihre uneingeschränkte Daseinsberechtigung haben, zum Abbilden dieser Schnittstelle ein, begehen wir einen Kategorienfehler. Versuchen wir mit unserer heutigen Zweiwertigen Mathematik Verhalten des Menschen zu ergründen und Erkenntnisse zu generieren, befinden wir uns also bestenfalls im gelben Bereich, da wir in Summe Mittel der komplizierten Welt nutzen. Heuristiken sind hier Hilfsmittel, da unsere Mathematik derzeit nichts anderes bietet. Ist der Mensch aus dem Spiel, landen wir, wenn wir die richtigen Algorithmen wählen, im grünen Bereich. Das können Sie an der Big Data Analytics Matrix abgebildet erkennen.
Nutzt man für die Schnittstelle von der materiellen in die seelische Welt einen Algorithmus, dann muss dieser natürlich den Menschen trivialisieren. Er muss ganz stark verallgemeinern. Die oben abgebildeten “m:n Beziehungen” lassen sich nicht programmieren, da die Konditionen für die Verzweigungen unbekannt sind. Sie sind abhängig vom jeweiligen Kontext des Menschen, der aber erst einmal wahrgenommen werden muss, um dann darauf reagieren zu können. Jeder Algorithmus ist auf Monokontexturalität aufgebaut, das heißt, die Kontexte und damit die Verzweigungen müssen dem Algorithmus ex ante mitgeteilt werden.
Beschreiben geht nur im Rahmen eines vorher gesetzten Kontextes. Das ist dann Messen. Das kann man mit Maschinen automatisch auf einer Datenbasis gestalten. Wahrnehmen bedeutet aber gleichzeitig das Setzen eines Kontextes, der nicht gegeben ist. Das kann eine Maschine nicht. 2 Beispiele dazu.
Was Menschen in einem Onlineshop tun, kann man tracken. Die Daten kann man erheben und speichern. Man kann aber nicht tracken, warum sie genau das tun, wie also die Gefühle hinter diesen Taten waren. Es kann also sein, sogar sehr wahrscheinlich, das zwei Menschen auf dem Onlineshop genau das Gleiche tun, aber unterschiedliche Beweggründe dafür haben.
Stellen sie sich eine Frau vor, die sich mit ihrem Mann streitet. Sie ist frustriert und kauft deshalb ein (Frustkäufe). In dem Kontext des “Kaufens” ist sie nicht frustriert. Sie will ja gerade ihren Frust mit dem Kaufen besiegen. Im Kontext ihres “Mannes” ist sie aber frustriert. Sie ist also beides gleichzeitig “frustriert” und “nicht frustriert”. Eine Maschine würde hier einen Fehler melden: Widerspruch. Wir Menschen können damit umgehen, da wir polykontextural denken und agieren, es aber nicht in Logik und damit Algorithmen verorten können.
An dieser Stelle möchte ich auch noch einmal auf das Lernen eingehen. Grundsätzlich sollte man Lernen in einen differenzierten Kontext setzen, was ich in meinem Artikel Können Maschinen entscheiden? auf der Plattform der Unternehmensdemokraten versucht habe. Dort spreche ich 3 verschiedene Lernarten an. Maschinen können nur Lernen_1. Lernen_1 funktioniert ausschließlich in genau einem vorher gesetzten bestimmten Kontext. Ein Parkassistent wird niemals Schach lernen, umgekehrt ein Schachcomputer niemals das Einparken eines Autos. Der Parkassistent hat den Kontext “Parke das Auto in die Parklücke ein.” Der Schachcomputer hat den Kontext: “Gewinne das Schachspiel unter Einhaltung der Regeln.”
Das Setzen des Kontextes geschieht durch den Menschen und zwar durch vorher bestimmte Eingangsparameter, auf deren Basis die Maschine einen bestimmten Output in dem gegebenem Kontext errechnen soll. Kontextwechsel bedeutet das Hinzunehmen neuer Eingangsparameter, die die Maschine nun wieder neu messen muss. Wahrnehmen funktioniert ja nicht, da die Sensoren der Maschine auf genau diese Daten justiert werden müssen und der Programmcode der Maschine geändert werden muss, um diese neuen Parameter zu verarbeiten um einen Output zu errechnen. Nach diesem Setzen der neuen Parameter inkl. der Anpassung der Sensoren der Maschine und des Programmcodes ist also der genau eine Kontext der Maschine erweitert worden. Damit agiert die Maschine natürlich weiterhin monokontextural. Da der Mensch durch seine Wahrnehmungs- und Denkprozesse das Ändern und Erweitern eines Kontextes von sich heraus alleine bewerkstelligen kann, spricht man davon, dass er polykontextural agiert.
Nun verliere ich noch ein paar Worte zu Heuristiken, um klarer zu machen, wo die Unterschiede zu Algorithmen liegen.
Heuristiken basieren niemals auf dem “WARUM”, sondern nur auf dem “WAS”, weil die Schnittstelle zwischen der materiellen und der seelischen Welt nicht beschreibbar ist. Wenn man beispielsweise erkennt, dass ein Kunde auf Newsletter nicht reagiert, sprich diese Mails niemals oder sehr selten öffnet (“WAS”), kann ich die Entscheidung treffen, diesem Kunden keine Newsletter mehr zu senden. Die hinter liegenden Gründe, “WARUM” der Kunde die Newsletter nicht oder selten öffnet, bleiben im Verborgenen, spielen für das Setzen der Heuristik “Kunden, die selten oder gar nicht auf Newsletter reagieren, bekommen keine Newsletter mehr” auch keine große Rolle.
Heuristiken basieren immer nur auf “Viele” und niemals auf einzelne Individuen, da sie stets auf Daten der Vergangenheit basieren. Hier wieder das Beispiel mit den Newslettern. Nur weil ich, Conny Dethloff, früher selten oder gar nicht auf Newsletter reagiert habe, bedeutet das nicht automatisch, dass ich auch in Zukunft niemals auf Newsletter reagieren werde. Wenn man diese Erkenntnis aber auf einer Basis von vielen Kunden gewinnen kann, ist die Vermutung groß, dass die vorher gesetzte Heuristik viabel ist, auch wenn sie für einzelne wenige Kunden nicht stimmen mag.
Entscheidungen, die also auf einem “WARUM” basieren, basieren nicht auf Heuristiken und unterliegen deshalb einem Kategorienfehler, da sie versuchen die Schnittstelle zwischen der materiellen und der seelischen Welt nachzubilden. Auch dazu wieder ein Beispiel. Ich referenziere auf die im letzten Post dargestellte Sales Attribution im Handel. Wir sind nicht im Stande, die gesamten Aktivitäten eines Kunden im Netz auf einen dedizierten Kauf eines Artikels zu mappen. An dieser Stelle verlasse ich das “WAS” und gehe in die seelische Welt über, versuche also das “WARUM” zu beantworten. Das ist nicht zulässig. Hier muss ich nach Heuristiken suchen, die einzig und allein auf dem “WAS” basieren. Lösungsmöglichkeiten habe ich für diesen Anwendungsfall im voran gegangenen Post gegeben.
Eines noch zum Schluss. Man könnte nun natürlich argumentieren.
Ja, okay. Auf Individuenebene kann ich das “WARUM” über Daten und Algorithmen automatisch ohne Zutun des Menschen nicht erkennen. Aber wenn ich diese Erkenntnisse gar nicht auf Individuenebene anwenden möchte (Quadrant IV der Big Data Anlytics Matrix), sondern auf “Viele” (Quadrant I der Big Data Anlytics Matrix), dann aggregiere ich ja diese Erkenntnisse. Damit bilde ich dann einen Durchschnitt und dann passt es wieder.
Stimmt das? Welche Mittel nutzen wir denn für das Aggregieren der Erkenntnisse? Richtig, Mittel der Zweiwertigen Mathematik. Passt also nicht. Ich habe im vorangegangenen Post Lösungsmöglichkeiten für solche Art von Anwendungsfälle gegeben. Das verbindende Element aller dieser Optionen ist der Einsatz von Heuristiken, die aber wie gesagt auch nur eine Annäherung ermöglichen.
Nun werde ich im kommenden Post dieser Reihe zum Thema Kennzahlen und Steuerung überleiten.
Eines nur schon mal vorweg. Mit dem bisher Gesagten wird auch meine These, dass der Mensch im Zuge der Digitalisierung immer mehr an Bedeutung gewinnt, deutlicher. Wir müssen keine Angst vor Maschinen haben. Sie helfen uns, aber nur in den Bereichen, wo wir bereits genügend Expertise und Wissen erlangt haben, und wo auch gar nicht mehr gefordert ist, bei Routinetätigkeiten. Wenn es um Erkenntnisgewinn und Innovation geht, dann können wir uns nur selber helfen. Wir müssen denken, denn Maschinen erkennen niemals das “WARUM”, nur das “WAS”.

 (8 Bewertung(en), Durchschnitt: 4.50 von 5)
(8 Bewertung(en), Durchschnitt: 4.50 von 5)
Pingback: [Reise des Verstehens] Maschinen kennen nur das “WAS”, niemals das “WARUM”
Pingback: Reise des Verstehens » Blog Archiv » Die Big Data Analytics Matrix
Pingback: Reise des Verstehens » Blog Archiv » Methoden passen immer, …
Pingback: Reise des Verstehens » Blog Archiv » Fördert Kybernetik die Steuerungsobsession von uns Menschen?
Pingback: Digitalisierung ist mehr als nur “0” und “1” | Reise des Verstehens