
Hypethemen der Wirtschaft, Service Oriented Architecture (SOA) oder Unternehmens Core Data Warehousing (CDW), um nur zwei der nahen Vergangenheit zu nennen, werden zu Beginn ihrer Entstehung extrem hoch gejubelt. Erwartungen werden in sie gesetzt, die sie so meistens nicht erfüllen können, da diese zu hoch gesteckt sind. Diese Hypethemen haben auch häufig einen Mantel der Technologie um, weil wir Menschen sowieso sehr häufig in der Technik unser Heil suchen, wie im Rahmen der Digitalisierung unserer Gesellschaft, mit der Wirtschaft als Teil davon, schön zu beobachten ist.
Warum sind nun die Erwartungen in solche Hypethemen so hoch? Das ist auf unseren zweiwertigen Denkrahmen zurückzuführen. Entweder etwas ist “gut” oder “schlecht”, etwas dazwischen darf nicht sein. In den Anfangstagen sind Hypethemen ausnahmslos “gut”. Ganz viel Hoffnung wird in sie hinein projiziert. Mit der Zeit nährt sich dann die Wahrnehmung, dass diese Hypethemen doch nicht die gesamte Wirtschaftswelt retten können und dann sind sie “schlecht”. Sie verschwinden von den Schauplätzen der Wirtschaft und werden verschmäht und verprügelt.
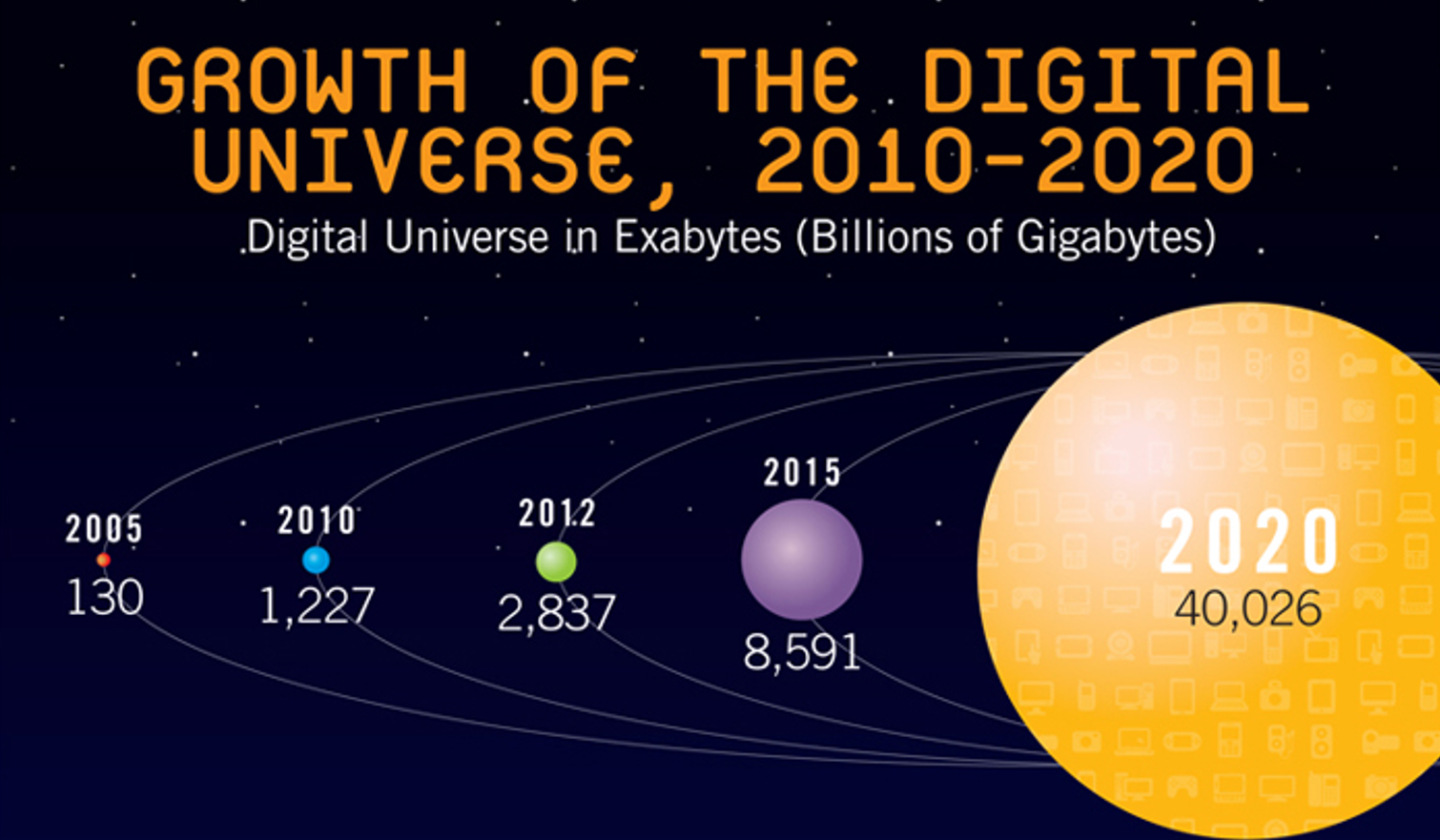
Wird dieses Schicksal “Big Data”, einem neuen Hypethema der Wirtschaft, ebenfalls zuteil? Ich befürchte es. Deshalb auch dieser Post, in welchem ich eine Sowohl-Als-Auch Haltung zum Thema Big Data einnehmen und verargumentieren möchte. Big Data ist also weder “gut” noch “schlecht”, sondern für bestimmte Fragestellungen eben passfähig und für bestimmte andere Fragestellungen eben nicht. Man sollte sich also der Grenzen des Einsatzes von Big Data bewusst sein, um diese dann auch mehrwertgenerierend im jeweiligen Kontext in der Wirtschaft einsetzen zu können.
Wo ist Big Data eher hinderlich?
Ich möchte gleich mal vorweg mit der Türe ins Haus fallen. Mit Big Data wird Bestehendes optimiert, Neues wird nicht erzeugt. Big Data verhindert Innovation und führt zu Stillstand. Der Grund? Daten entstehen aus Handlungen der Vergangenheit und zeichnen damit vergangene Handlungen nach und auf. Datenanalysen sind immer der Versuch, Schlüsse für die Zukunft aus der Vergangenheit zu ziehen. Der Blick auf Daten, egal mit welchen Verfahren oder Tools, sind stets ein Blick in den Rückspiegel. Wie wurde wohl beispielsweise das iPhone erfunden? Durch Erkennen von Zusammenhängen in Daten, die aufgezeigt haben, dass Menschen gerne Touchscreens bedienen möchten? Wohl kaum.
Ich spreche hier also das Thema Innovation und Kreativität in Zusammenhang mit Datenanalysen. Gegen Ende des Posts noch einmal mehr dazu.
Sie erkennen wahrscheinlich schon, wo die Hürde im Umgang mit Big Data liegen könnte. Es geht um einen adäquaten passgerechten Mindset als Basis für Datenanalysen. Wenn ich nur auf “Datacrunching” und das Erkennen von Muster in Daten aus bin, mich kopfmäßig davon nicht lösen kann und mal meine Intuition zu Worte kommen lasse, dann erkenne ich genau diese möglichen neuen Produkte nicht, die Kunden begeistern könnten.
Oft wird bereits der Umgang mit Daten im Kontext von Entscheidungen als innovativ betrachtet. Nur weil man vielleicht im Kontext des Einsatzes von Tools und Methoden auf dem neuesten Stand der Technik ist. Das ist für mich aber eben nicht innovativ. Innovation hat für mich etwas mit Musterbrechen zu tun. Mit Datenanalysen lassen sich Muster aufdecken, auf deren Basis man dann wiederum Entscheidungen trifft. Damit schreibt man dann die Vergangenheit in die Zukunft fort. Allerdings werden damit direkt keine Innovationen angekurbelt, ganz im Gegenteil. Ich verstehe Musterbrecher auf einer anderen Ebene, nicht WAS man tut ist entscheidend, sondern mit welchem Mindset und welcher Intention ETWAS getan wird. Mit dem alleinigen Auffinden Wollen von Mustern (Korrelationen) zwischen Daten schreibt man einzig etwas bereits Dagewesenes Vorhandenes nach vorne hin fort und trifft auf dieser Basis Entscheidungen. So entstehen aber keine innovativen Lösungen. Innovationen lassen sich nicht entdecken, sondern nur erfinden.
Es gibt einige Beispiele von Firmen in der Wirtschaft, wo das alleinige Fortschreiben von Mustern in die Zukunft lebensbedrohlich wurde. Schauen wir einmal auf Nokia im Handymarkt, die den Wandel zum Smartphone nicht erkannt haben. Kodak wäre hier auch zu nennen, die den Wandel hin zur Digitalfotografie verschlafen haben. Solche Zeitpunkte sind Musterbrüche, die sich nicht ohne weiteres in den Daten erkennen lassen, da Daten immer nur die Vergangenheit abbilden. Musterbrüche lassen sich nicht in Korrelationen zwischen Daten aufdecken.
Und grundsätzlich ist auch der Umgang mit Daten an sich, um in Unternehmen Entscheidungen herzuleiten, nicht neu. Seit x Jahrzehnten schon werden in Unternehmen Berichte ohne Ende produziert, um auf dieser Basis zu entscheiden. Heute nutzen wir nur zusätzlich mehr und verschiedenartigere Daten, die schneller erzeugt werden, sowie dazu noch analytische Modelle. Das hier das Neuartige fehlt, möchte ich kurz andeuten.
Entweder werden analytische Modelle im Kontext Daten genutzt, um Handlungen der Vergangenheit zu erklären, um auf dieser Basis Entscheidungen zu treffen. Stichwort Sales Attribution im Handel. Es wird analysiert, wie hoch der Beitrag der einzelnen Onlinekanäle (Search Engine Advertising (SEA), Search Engine Optimization (SEO), Preissuchmaschinen (PSM), …) auf den eigentlichen Ertrag ist, wenn der Kunde nämlich einen Artikel kauft, um auf dieser Ratio eine zukünftige Budgetzuteilung auf die Onlinekanäle vorzunehmen. Hier ist sehr einfach ersichtlich, dass die Vergangenheit in die Zukunft fortgeschrieben wird. Also nur Optimierung des bereits Vorhandenen und keine Innovation.
Des Weiteren werden analytische Modelle aber auch genutzt, um wirtschaftliche Optimierungsaufgaben zu lösen. Dabei werden über Korrelationsanalysen Treiber für eine zu optimierende Zielgröße gesucht. Diese sind dann Inputfaktoren für das Modell, welches die Zielgröße optimieren soll. Die Güte des Modells wird dann gegen Sampledaten aus der Vergangenheit durch Testen festgestellt. Je besser ein Modell die Konstellation der Vergangenheit nachstellen kann, um so besser. Was wird hier getan? Richtig. Wieder kein Musterbrechen, da sowohl die Korrelationsanalysen als auch das Testen auf Daten der Vergangenheit beruhen. Also Optimierung des bereits Vorhandenen und keine Innovation.
Ich möchte nicht falsch verstanden werden. Big Data ist an sich nicht schlecht. Ich bin hier nur auf eine Hürde im Kontext Big Data eingegangen, die, wenn sie nicht genommen wird, einer Mehrwertgenerierung im Wege steht. Es ist unsere Geisteshaltung, mit diesen Daten zu agieren, um Innovation anzukurbeln. Innovationen entstehen in vielen Fällen durch Zufall. Wir versuchen aber über Big Data genau diesen Zufall zu killen. Warum? Weil er uns Unbehagen und schlaflose Nächte bereitet. Wir können dann nicht mehr steuern und kontrollieren.
Bleiben wir kurz beim Erkenntnisgewinn im Umgang mit Big Data und den darauf “losgelassenen” Algorithmen. Was erzielen Algorithmen für Ergebnisse? Dazu möchte ich auf einen sehr interessanten Artikel verweisen und hier kurz darauf eingehen. Neuronal Netze werden oft zur Bilderkennung eingesetzt. In diesem Kontext haben sich Forscher die Frage gestellt, wovon diese trainierten Netze eigentlich träumen, oder nicht ganz so philosophisch ausgedrückt, wieviel Erkenntnisgewinn eigentlich in Anwendung solcher Netze steckt. Das Ergebnis? Sehr wenig Erkenntnisgewinn. Denn ein Neuronales Netz, welches beispielsweise auf das Erkennen von Bananen trainiert wurde, erkennt in jedem Bild Bananen. Es bestätigt sich also jedes Mal immer wieder selber.
Was bedeutet das aber jetzt für uns im Umgang mit Big Data? Ein “Mehr” an Daten führt nicht unbedingt immer zu “Mehr” an Erkenntnis. Wir müssen also immer noch unseren Kopf gebrauchen, um Innovationen herbeizuführen und dürfen uns nicht ganz den Daten hingeben. Wir benötigen also eine differenzierte Betrachtung von Big Data und dazu möchte ich auch mit diesem Post anregen.
Wo kann “Big Data” helfen?
Big Data erklärt Zusammenhänge der Vergangenheit und kann daher bestimmte Ergebnisse aus Aktionen der Vergangenheit erklärbarer machen. Dabei muss aber Klarheit über ein paar Begrifflichkeiten herrschen, die oftmals miteinander verwechselt werden. Es geht um Koinzidenz, Korrelation und Kausalität, auf die ich hier detaillierter eingehe. Ein Verständnis in diesem Kontext ist von immenser Bedeutung, will man Entscheidungen auf Basis von Geschehnissen der Vergangenheit ableiten. Ein Beispiel dafür ist ebenfalls über den oben aufgeführten Link angeführt, um die Unterschiede der 3 Begriffe transparent zu gestalten. Skurrile weitere Beispiele zur Verwechslung zwischen Korrelation und Kausalität können Sie hier einsehen. Beispiel: Die Anzahl der Filmauftritte von Nicolas Cage pro Jahr stimmt mit der Anzahl der Menschen, die in den USA in einem Pool ertrinken, überein. Will man diesen Fakt Nicolas Cage wirklich anlasten?
Angenommen, wir haben also klare Ursachen für bestimmte wahrgenommene Ergebnisse ausfindig machen können, das Dickicht zwischen Koinzidenz, Korrelation und Kausalität also klären können. Was wir wir mit dieser Erkenntnis im Kontext zukünftiger Handlungen anstellen sollen, erzählen uns diese Daten nicht. Dazu benötigen wir den Menschen. Dazu ein paar Beispiele aus dem Handel und meinem persönlichen Kaufverhalten. An meinen getätigten Käufen kann man beispielsweise erkennen, dass ich, wenn ich Sportschuhe kaufe, eher die Marke Adidas bevorzuge, als die Marke Puma. Nimmt man diesen Fakt als Basis für eine Entscheidung, um mir Sportschuhe anbieten zu wollen, sollte man mir wohl eher Adidas-Schuhe zeigen, unter der Vermutung, dass sich meine Affinität in diesem Kontext nicht so schnell ändert. Hier kann man also die Vergangenheit in die Zukunft fortschreiben. Stellen wir uns aber einen weiteren Fakt vor. Ich bin in der Regel kein Schnäppchenkäufer. Wenn ich also beispielsweise Gutscheine angeboten bekomme, die mir bei einem nächsten möglichen Kauf einen bestimmten Rabatt zusichern, landen diese Dinger sehr oft im Müll. Das muss aber nicht heißen, dass ich grundsätzlich und in jeder Lebenslage Rabatte verweigere. Hier bin ich Mensch und gebe dem Zufall eine Chance, bin damit also nicht immer durchschaubar. Das ist ja auch gut so, sonst wäre das Leben ja langweilig. Ob das allerdings die Algorithmen ebenfalls so sehen? 🙂
Der Bogen zwischen dem “Guten” und dem “Bösen” an Big Data …
kann einzig und allein durch den Menschen geschlossen werden. Ist das nicht erfreulich? Denn, Big Data und die ausgeklügelten analytischen Werkzeuge, die darauf aufsetzen, erlauben es uns, nahezu sämtliche Prozesse effizienter zu gestalten. Intuition und Kreativität werden bald die einzigen Unterscheidungsmerkmale unter den Wettbewerbern sein, um mittels Innovationen Produkte und Leistungen zu generieren, die durch Kunden als mehrwertig eingestuft werden. Aber dazu benötigen wir den Menschen. Die Werkzeuge und Tools, und seien sie auch noch so fortschrittlich und technisch ausgereift, können aus Big Data nicht die vielleicht erhofften Erkenntnisse extrahieren, da diese nur den Blick in den Rückspiegel erlauben. Innovation und Kreativität geht nicht durch Maschinen.
Treiber für Innovation ist nicht der Kunde und dessen vermeintliches Wissen um eigene künftige Bedürfnisse, also Marktforschung. Sondern konkrete Ideen beliebigen Ursprungs und die Kreativität der Mitarbeiter in Unternehmen. Es geht darum, tatsächlich überraschende Produkte zu schaffen und insofern dem Markt voraus zu sein. Denn im Zusammenhang mit Menschen haben wir es stets mit komplexen Situationen zu tun, und da hilft kein Wissen, weil Wissen dazu nicht existiert. In komplexen Situationen hilft nur Können, Talent und Phantasie. Daten werden aber in der Regel für Wissensaufbau genutzt. Das Entscheidende für Innovationsfähigkeit in Unternehmen ist nicht, Ideen zu befördern – die hat jeder, ständig. Entscheidend ist, Kreativität zu begünstigen bzw. zuzulassen. Den sozialen Prozess, der Ideen in Innovationen umwandelt, nennt man Kreativität. Kreativität ist also ein kollektives Phänomen und Innovation stets Teamleistung, und damit etwas sehr Menschliches.
Ständiges Verlangen nach Daten ist ein Zeichen für Innovationsschwäche. Denn Innovation bedeutet Neues zu erfinden, nicht zu erkennen. Erkennen lässt sich nur etwas Vorhandenes. Das bedeutet aber auch, dass das Risiko bei Entscheidungen im Kontext von Innovationen, also unternehmerische Entscheidungen, hoch gehalten werden muss. Der Drang nach Unsicherheitsabsorption ist hier fehl am Platze. Je größer das Risiko und damit je größer die Unsicherheit, desto größer ist auch die Chance auf Innovation.
Ich habe zwei Themen in diesem Post nicht oder nur sehr kurz beleuchtet, nämlich den Datenschutz und den “Sinn” bzw. Relevanz von Daten. Es geht nicht darum stets ein Mehr an Daten zu haben, sondern für bestimmte Fragestellungen relevante Daten zur Verfügung zu haben. Dieses Herausfiltern der Relevanz ist eine Kunst, die, wenn sie nicht beherrscht wird, zu einer absoluten Beliebigkeit in der Erkenntnisgewinnung aus Daten führt. Dann ist nämlich Alles und Nichts erklärbar, je nach Hypothese, die durch Daten eigentlich erst bestätigt werden soll. Einer meiner Wegbegleiter hat zu beiden Themenstellungen einen sehr interessanten Post namens Big Data – Was du letzten Sommer nicht getan hast, auf den ich gerne in diesem Kontext verweise.
 (1 Bewertung(en), Durchschnitt: 5.00 von 5)
(1 Bewertung(en), Durchschnitt: 5.00 von 5)
Pingback: [Reise des Verstehens] Dem Big Data Hype ein wenig Erdung einverleiben